 |
|
BVS-LILACS versión 1.4 |
| BIREME home page: www.bireme.br | Metodología LILACS: www.bireme.br/abd/ |
| e-mail: peml@bireme.br | |
Manual de Instalación
Sumario
| Descripciˇn del Sistema |
LILDBI significa LILACS Descripción Bibliografica e Indización, el objetivo principal del sistema LILDBI WEB es permitir una alimentaciˇn descentralizada de bases de datos bibliogrßficas basadas en la metodología LILACS, el manejo de las mismas y un control de calidad. La aplicación está escrita en IsisScript para ser ejecutada con el Servidor WWWISIS XML IsisScript - WXIS y tiene funciones desarrolladas en PHP.
Actualmente, muchos centros cooperantes usan el LILDBI para alimentar bases regionales o locales. Esas bases generalmente no siguen rigurosamente la metodologÝa LILACS, poseyendo campos diferentes para almacenar otros tipos de informaciones.
La versiˇn Web del LILDBI es configurable de manera que posibilite que cada centro pueda adaptarlo, creando sus propios campos. No obstante, deben existir mecanismos para garantizar el cumplimiento de las reglas de la metodologÝa en los datos enviados para LILACS.
Las principales caracterÝsticas del sistema son:
- multiusuario;
- prealmacena los datos en el momento de la digitaciˇn en bases temporales;
- alimenta la base de datos solamente a partir de esas bases temporales permitiendo una fuerte consistencia;
- configura la consistencia de los datos y;
- permite la creaciˇn de campos no usados por la metodologÝa LILACS.
| Funcionamiento del Sistema |
Al instalarse el BVS-LILACS es instalado:
- una base LILACS patrˇn sin ning˙n registro y;
- un usuario patrˇn ADMLILACS con los 3 permisos de acceso al sistema: administrador, editor y documentalista (la clave es ADMLILACS).
Permisos de acceso
Existen 3 tipos de permisos: administrador, editor y documentalista.
Un mismo usuario puede tener uno o mßs permisos de acceso.
El permiso de administrador posibilita al usuario configurar el sistema, registrar usuarios, alterar los permisos de los otros usuarios, hacer el mantenimiento de la base, o sea, todo lo que sea relativo a la administraciˇn del sistema y de la base de datos.
El permiso de documentalista permite la entrada y modificaciˇn de registros y su certificaciˇn. En este permiso, el usuario no puede editar registros certificados.
Ya en el permiso de editor, el usuario puede editar registros de la base certificada, pero no puede crear nuevos registros.
Las funciones de cada permiso son:
- Administrador:
configurar el sistema;
registrar los usuarios;
definir las permisiones de acceso de cada usuario;
definir los campos de la base de datos;
definir consistencias de cada campo;
- Documentalista:
crear nuevos registros no certificados;
editar los registros no certificados;
certificar registros;
importar registros;
- Editor:
editar los registros ya certificados;
enviar documentos certificados para BIREME;
generar informes de la base certificada.
Certificaciˇn de registros
Durante la descripciˇn y la indizaciˇn de un documento, el sistema almacena los datos en una base no certificada. Para el trabajo ser concluido, el documentalista tendrß que certificar los documentos.
Al certificar un documento, el sistema ejecuta la consistencia definida por el administrador para cada uno de los campos. Pasando por la consistencia los documentos serßn transferidos para la base de datos, siendo eliminados de la base no certificada del documentalista. Si durante la consistencia fueron identificados errores, los registros serßn mantenidos en la base no certificada, y el sistema generarß un informe para que el documentalista lo corrija.
Cada base de datos alimentada por el LILDBIWEB tendrß una base principal certificada ademßs de una base de trabajo no certificada para cada documentalista registrado.
| ¿Dónde se instala el sistema? |
La aplicación debe ser instalada bajo un servidor Web. Dos otros recursos deben ser instalados en el servidor. El programa WXIS que es un servidor de acceso multiusuario a bases de datos ISIS (este software viene junto al paquete de instalación); y el software PHP (www.php.net).
|
En todo servidor Web existe una estructura de directorios para su operación. A los efectos de los ejemplos de este manual se asumirá que la estructura de directorios es la que se enseña en la figura a la derecha. En general existen equivalencias entre los directorios de los servidores Web y la estructura propuesta en la figura 1. La tabla siguiente muestra otras estructuras similares para servidores Web en el mercado. Es posible hacer adaptaciones y variantes a este esquema para acomodar los directorios de acuerdo a implementaciones específicas. |
|
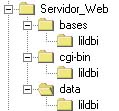
| Propuesto | OmniHTTPd | MS IIS | Apache |
| Servidor_Web | httpd | Inetpub | Apache |
| Cgi-bin | cgi-bin | scripts | cgi-bin |
| Data | htdocs | wwwroot | htdocs |
| ¿Quién Instala el Sistema? |
Para instalar la aplicación es necesario tener los conocimientos básicos para realizar las operaciones de mantenimiento de sistemas computarizados, tales como la creación y eliminación de directorios, copia, edición y eliminación de archivos, asignación de derechos de acceso, etc., además tener conocimientos del servidor Web a ser utilizado.
| Paquete de Instalación |
El paquete del sistema se distribuye en un directorio llamado bvs-lilacs con todos los archivos y subdirectorios necesarios. A creación del directorio, depende de la plataforma operativa. Para sistemas Windows 9x/2000/NT es enviado un ejecutable (bvs-lilacs.exe), que después de ejecutado crea un directorio conforme ilustrado en la Figura-2 (para ejecutar: Botón Iniciar ® Ejecutar ® "d:\bvs-lilacs.exe"). Para sistemas LINUX y similares es enviado un archivo TAR GZ (bvs-lilacs.tgz), que después de abierto crea un directorio conforme ilustrado en la Figura-2 (para abrir el archivo ejecute el comando: tar xvfzp bvs-lilacs.tgz). El paquete está compuesto por tres conjuntos de archivos: el conjunto bases, el conjunto cgi-bin y el conjunto data. Cada uno de esos contiene un subdirectorio llamado lildbi. Bajo cada uno de estos subdirectorios existen a su vez otros subdirectorios, tal como se describen a continuación. |
|
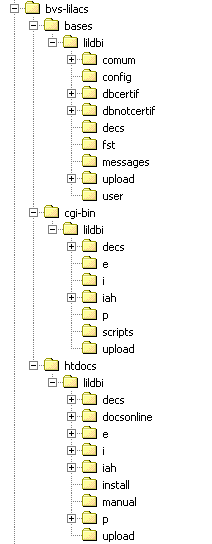
| ruta BVS-LILACS/BASES/LILDBI |
En el directorio están las bases de datos de configuración; tablas auxiliares para el ingreso de registros; tablas de selección de campos para aplicarse a las bases; formatos de verificación de campos; bases de datos de trabajo para los documentalistas y la base de dados certificada.
| ruta BVS-LILACS/HTDOCS/LILDBI |
Este directorio contine las imagenes usadas en la interface, teales como íconos, botones, banners, logos e etc; archivos con los textos de ayuda de la metodología LILACS en formato HTML; el archivo de configuración general del sistema (LILDBI.DEF) y los módulos auxiliares escritos en PHP para upload de archivos ISO e transferencia de archivos FTP.
| ruta BVS-LILACS/CGI-BIN |
Aquí se encuentra el programa WXIS1660.EXE que interpreta y ejecuta el contenido de los scripts.
| ruta BVS-LILACS/CGI-BIN/LILDBI |
Aquí están los scripts del sistema y los archivos de formato, usados para montar las diversas partes de las páginas que componen la interface, en sus idiomas correspondientes.
| ¿Como Instalar el Sistema? |
Los directorios y archivos mencionados deben ser copiados en los lugares adecuados al servidor Web, como veremos en los detalles a continuación; primero de todo es necesario conocer algunos datos sobre el servidor Web que recibirá la interface. Debe recopilarse las siguientes informaciones:
- Sistema operativo (ej.: LINUX, Windows NT, etc.);
- Raíz del servidor Web (ej.: /Apache/HtDocs);
- Directorio de ejecución de CGI / Scripts (ej.: /Apache/cgi-bin);
- Ubicación de las Bases de Datos (ej.: /Apache/bases).
Para implantar la interface, aquí llamada de aplicación, serán creados directorios respectivos para cada uno de los componentes.
La descripción que sigue muestra un proceso de instalación estándar para la interface, o sea usando lildbi como nombre de la aplicación, basado en el servidor Web Apache en su configuración patrón de directorios (ver Tabela-1).
| Directorios para las Bases de Datos |
|
Como se explicó anteriormente (ver Figura-1), en la estructura de directorios del servidor Web, hay una ubicación específica para almacenar las bases de datos. En la Figura-3, a la derecha, se muestra el esquema de directorios para la instalación del paquete de distribución. |
|
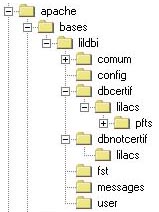
| Procedimientos para la instalación del paquete: |
1. Transferir para el directorio donde estarán las bases en el servidor Web, los archivos presentes en /bvs-lilacs/bases del paquete de instalación, así como sus subdirectorios (ver Figura-2).
| Directorios para las Páginas de Acceso a la Interface |
En el servidor Web debe haber un directorio para almacenar las páginas estáticas de acceso a la aplicación, además de subdirectorios para: imágenes y ayuda en cada uno de los idiomas de la interface. Este directorio debe estar debajo de la raíz del servidor Web y tendrá el mismo nombre de la aplicación. La Figura-4 a la derecha muestra la ubicación del directorio de la aplicación (lildbi), debajo del directorio raíz del servidor Web (Apache/HtDocs), en este directorio estará el archivo con extensión DEF utilizado para almacenar las configuraciones de la aplicación . |
|
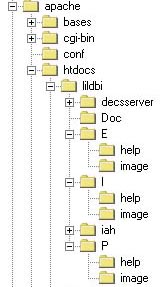
| Procedimientos para la instalación del paquete: |
1. Transferir para el directorio raíz del servidor Web (directorio de páginas html), los directorios presentes en /bvs-lilacs/htdocs del paquete de instalación, así como sus subdirectorios (ver Figura-2).
| Directorio para la Ejecución de Scripts |
En el servidor Web debe haber un directorio de ejecución de CGI, en este directorio debe ser colocado el programa WXIS1660.EXE y debajo de este directorio estará un directorio para la aplicación (en nuestro ejemplo lildbi) que contendrá los archivos de IsisScript correspondientes a la aplicación. |
|
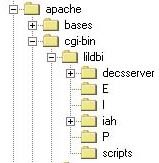
| Procedimientos para la instalación del paquete: |
1. Transferir para el directorio de ejecución de cgi / scripts del servidor Web los archivos existentes en /bvs-lilacs/cgi-bin del paquete de instalación, así como sus subdirectorios.
| Setup Inicial del Sistema |
Después de copiar los archivos del sistema
, debese abrir la página inicial de configuraciˇn
con un navegador de web, utilizando la dirección:
http://servidor/lildbi/install/setup.php, donde
servidor será el nombre de su servidor Internet donde
está instalado el paquete. Si la instalación se está
haciendo localmente en el servidor, es posible usar
localhost como nombre
del servidor. ATENCIËN: Antes de iniciar el setup ajuste los permisos
de los siguientes directorios en el servidor:
http://servidor/lildbi/index.htm
Prueba Inicial
del Sistema
A partir de esta pßgina se puede acceder a la pßgina de administraciˇn de la base de datos y el sistema de b˙squeda en los tres idiomas.
| Substituyendo la Base LILACS del Sistema |
Para sustituir la base de datos certificada que viene el en paquete de instalacion del sistema siga los procedimientos a continuaciˇn:
1. Transferir para el directorio de bases certificadas (bases/lildbi/dbcertif/lilacs) el archivo ISO de la nueva base de datos;
2. Ejecutar el programa de generaciˇn da base certificada en linea de comando:
2.1. En ambiente windows abra una ventana DOS;
2.2. Cambie para el directorio de bases de datos certificada (ej.: /apache/bases/lildbi/dbcertif/lilacs);
2.3. Ejecute el procedimiento de generaciˇn informando el nombre del archivo ISO (incluyendo extensión). ATENCIËN: Este procedimiento borrarß todos los registros de la base de datos.
2.3.1. En ambiente DOS ejecute :
( gencertif.bat base.iso ) 2.3.2. En ambiente Linux o similares ejecute :
( ./gencertif.sh base.iso )
| Apéndice A - Técnicas de Indización |
Una FST (Field Select Table) consiste en una o más líneas, cada una de las cuales define tres parámetros:
1 - un identificador de campo;
2 - una técnica de indización;
3 - un formato de extracción de datos en el lenguaje de formateo de CDS/ISIS.
Las técnicas de indización definen los procesos a ser realizados sobre los datos generados por el formato, con objeto de identificar los elementos específicos que serán creados. Hay nueve (9) técnicas de indización que se pueden utilizar. Estas reciben un código numérico del 0 al 8, tal como se explica a continuación:
| a. Técnica de indización 0 (cero) |
Genera un elemento a partir de cada línea extraída por el formato. Esta técnica es normalmente utilizada para indizar campos o subcampos completos. Nótese sin embargo, que CDS/ISIS construirá elementos a partir de líneas, no de campos. Esto se debe a que CDS/ISIS considera la salida del formato como una cadena de caracteres, donde los campos no son identificables sino las líneas resultantes. Es responsabilidad del usuario producir los datos correctos mediante el formato, especialmente si está indizando campos repetibles o concatenando más de un campo. En otras palabras, cuando se usa esta técnica, el formato de extracción debe producir como salida una línea por cada elemento a ser indizado.
| b. Técnica de indización 1 (uno) |
Genera un elemento a partir de cada subcampo o de cada línea extraída por el formato. Como CDS/ISIS buscará códigos delimitadores de subcampos en la salida del formato, para que esta técnica trabaje correctamente el formato debe especificar el modo proof (o sin modo alguno, ya que este es el modo implícito), debido a que éste es el único modo que conserva los códigos delimitadores de subcampos en la salida. Recuerde que los modos de encabezamiento y de datos sustituyen los códigos delimitadores de subcampos por signos de puntuación. La técnica 1 de selección de términos es una extensión de la técnica 0.
| c. Técnica de indización 2 (dos) |
Genera un elemento a partir de cada término o frase encerrada entre paréntesis triangulares < ... >. Cualquier texto fuera de estas marcas no se incluye en el índice. Nótese que para usar esta técnica se necesita usar el modo proof, ya que los otros modos eliminan los paréntesis triangulares.
Por ejemplo:
Relatório descrevendo um <curso universitário> em <treinamento de documentação> em uma <escola de biblioteconomia> africana
Producirá los elementos siguientes indizados mediante esta técnica:
curso universitário;
treinamento de documentação;
escola de biblioteconomia.
| d. Técnica de indización 3 (tres) |
Realiza el mismo proceso que la técnica 2 excepto que los términos o frases están encerradas entre barras inclinadas ( /.../ ).
Por ejemplo:
Relatório descrevendo um /curso universitário/ em /treinamento de documentação/ em uma /escola de biblioteconomia/ africana
Producirá los elementos siguientes indizados mediante esta técnica:
curso universitário;
treinamento de documentação;
escola de biblioteconomia.
| e. Técnica de indización 4 (cuatro) |
Genera un elemento a partir de cada palabra en el texto extraído por el formato. Una palabra es cualquier secuencia de caracteres alfabéticos contiguos. Nótese que cuando esta técnica se usa para indizar un campo completo que contiene delimitadores de subcampo, debe especificarse el modo de encabezado o el de datos (mhl o mdl) en el formato de extracción de datos correspondiente, de manera que se realice la sustitución de los delimitadores de subcampo antes de la indización, de otra forma los códigos delimitadores de subcampo serán considerados como parte de la palabra. También es aconsejable usar el modo de encabezamiento de datos si el campo indizado contuviera información para archivo (filing elements).
- Observación::
- La definición de los caracteres alfabéticos puede ser adaptada a las necesidades de cada usuario mediante la Tabla del Sistema ISISAC.TAB.
| f. Técnicas de indización 5, 6, 7, y 8 |
Las técnicas de indización 5, 6, 7, y 8 operan de forma idéntica a las técnicas 1, 2, 3, y 4, respectivamente, pero permiten especificar un prefijo para los términos extraídos.
El prefijo se especifica en el formato de extracción de datos como un literal incondicional de la siguiente manera:
'dprefixod',[formato CDS/ISIS]
donde:
| d | es el delimitador elegido que no será usado como parte del prefijo; |
| prefixo | cadena de caracteres que será usado como prefijo; |
| [formato CDS/ISIS] | formato de extracción de datos en lenguaje de formateo CDS/ISIS. |
Por ejemplo, para indizar cada palabra del campo 24 con el prefijo TI_ se debe montar la FST con la declaración siguiente:
24 8 '#TI_#',v24
que se descompone en los siguientes elementos:
| '#TI_#' | literal incondicional | |
| # | delimitador de prefijo | |
| TI_ | prefijo usado | |
| V24 | formato de extracción de CDS/ISIS |
A los efectos de comparación podemos observar, en la tabla siguiente, una FST con y sin uso de prefijos:
| Sin Prefijo | Con Prefijo |
| 70 0 MHU,(V70/) | 70 0 MHU,('AU_',V70/) |
| 24 4 MHU, V24 | 24 8 MHU,'/TI_/',V24 |
| 69 2 V69 | 69 6 '/KW_/',V69 |
Es importante notar que la técnica de indización 0 (cero) admite el uso o no de prefijos, en cambio las otras técnicas deben ser especificadas, como se muestra en la tabla siguiente:
| Sin Prefijo | Con Prefijo | Operación de la técnica | ||
| 0 | ^ | 0 | ^ | Campo completo |
| 1 | ^ | 5 | ^ | Subcampo |
| 2 | ^ | 6 | ^ | Términos marcados com < ... > |
| 3 | ^ | 7 | ^ | Términos marcados con / ... / |
| 4 | ^ | 8 | ^ | Palabra por palabra |
| Apéndice B - Campos LILACS (Metodología BIREME) |
| CODIGO DEL CENTRO | [01] |
| NUMERO DE IDENTIFICACIÓN | [02] |
| LOCALIZACION DEL DOCUMENTO | [03] |
| BASE DE DATOS | [04] |
| TIPO DE LITERATURA | [05] |
| NIVEL DE TRATAMIENTO | [06] |
| NUMERO REGISTRO | [07] |
| MEDIO ELECTRONICO | [08] |
| AUTOR (nivel analÝtico) | [10] |
| AUTOR COLECTIVO (nivel analÝtico) | [11] |
| TITULO (nivel analÝtico) | [12] |
| TITULO TRADUCIDO AL INGLES (nivel analÝtico) | [13] |
| PAGINAS (nivel analÝtico) | [14] |
| AUTOR (nivel monogrßfico) | [16] |
| AUTOR COLECTIVO (nivel monogrßfico) | [17] |
| TITULO (nivel monogrßfico) | [18] |
| TITULO TRADUCIDO AL INGLES (nivel monogrßfico) | [19] |
| PAGINAS (nivel monogrßfico) | [20] |
| VOLUMEN (nivel monogrßfico) | [21] |
| AUTOR (nivel colecciˇn) | [23] |
| AUTOR COLECTIVO (nivel colecciˇn) | [24] |
| TITULO (nivel colecciˇn) | [25] |
| NUMERO TOTAL DE VOLUMENES (nivel colecciˇn) | [27] |
| TITULO (nivel serie) | [30] |
| VOLUMEN (nivel serie) | [31] |
| NUMERO DEL FASCICULO (nivel serie) | [32] |
| ISSN | [35] |
| INFORMACION DESCRIPTIVA | [38] |
| IDIOMA DEL TEXTO | [40] |
| IDIOMA DEL RESUMEN | [41] |
| TESIS Y DISERTACIËN - INSTITUCION A LA CUAL SE PRESENTA | [50] |
| TESIS Y DISERTACIËN - TITULO ACADEMICO | [51] |
| CONFERENCIA - INSTITUCIËN PATROCINADORA | [52] |
| NOMBRE DE LA CONFERENCIA | [53] |
| CONFERENCIA ľ FECHA | [54] |
| CONFERENCIA - FECHA NORMALIZADA | [55] |
| CONFERENCIA ľ CIUDAD | [56] |
| CONFERENCIA ľ PAIS | [57] |
| PROYECTO - INSTITUCIËN PATROCINADORA | [58] |
| NOMBRE DEL PROYECTO | [59] |
| PROYECTO ľ NUMERO | [60] |
| NOTAS | [61] |
| EDITORIAL | [62] |
| EDICIËN | [63] |
| FECHA DE PUBLICACIËN | [64] |
| FECHA NORMALIZADA | [65] |
| CIUDAD DE PUBLICACIËN | [66] |
| PAIS DE PUBLICACIËN | [67] |
| SIMBOLO | [68] |
| ISBN | [69] |
| TIPO DE PUBLICACIËN | [71] |
| NUMERO TOTAL DE REFERENCIAS | [72] |
| ALCANCE TEMPORAL (DESDE) | [74] |
| ALCANCE TEMPORAL (HASTA) | [75] |
| DESCRIPTOR PRECODIFICADO | [76] |
| INDIVIDUO COMO TEMA | [78] |
| OTRAS LOCALIDADES | [82] |
| RESUMEN | [83] |
| DESCRIPTORES PRINCIPALES | [87] |
| DESCRIPTORES SECUNDARIOS | [88] |
| FECHA DE PROCESAMIENTO | [91] |
| DOCUMENTALISTAS | [92] |
| REGISTRO COMPLEMENTARIO (MONOGRAFIA, COLECCION O SERIE) | [98] |
| REGISTRO COMPLEMENTARIO (EVENTO) | [101] |
| REGISTRO COMPLEMENTARIO (PROYECTO) | [102] |
| REGISTRO COMPLEMENTARIO (TESIS) | [103] |